Overview
Our data was collected using the TAGS client. Essentially, TAGS is a Google Sheets interface to interact with Twitter’s REST API. Using TAGS, Tweets were searched for in real-time using the Keyword: all tweets containing the token ‘riot’ or ‘#riots’ were included in our corpus. The data collection began at 11 pm UTC on the day of the insurrection (January 6th) and continued until 4 pm UTC on the 8th. So, Tweets weren’t collected in real-time as the riots were happening, but the tweets about the fallout and immediate reactions/analysis to the instructions were. In all, there were 269,190 tweets and 54,033 unique tweets.
The data includes the Twitter-generated ID strand per user, the username of the person the tweet originated from, the text of the tweet, the time the tweet was created, the profile image of each user, the numbers of followers and friends each user had at the time of collection, the user’s location (set by user, not geo-coordinates), symbols and hashtags used, and user mentions. The data also includes links to any multimedia included in each tweet. For tweets that were replies, the data also includes the user the person was replying to. For the purposes of our research, we looked mostly at the text of the tweet, the usernames for the top-circulated tweets, and images shared.
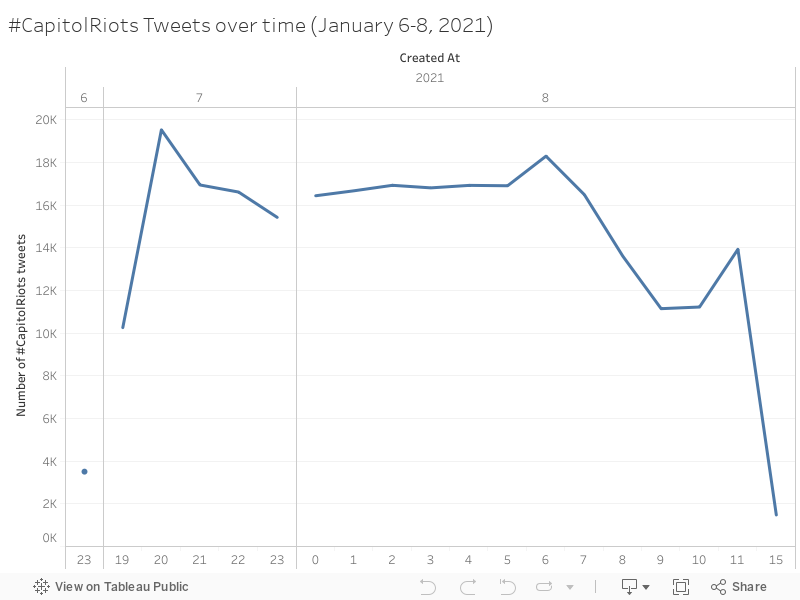
This timeline illustrates the number of tweets collected per hour over the 3 days our data comes from. There is very little data from the day of the insurrection attempt itself. Our data encompasses tweets between 11 pm UTC (6 pm EST) on the day of the insurrection attempt (Jan. 6) and 4 pm (11 am EST) two days after (the day President Donald Trump was banned from Twitter). As noted, the time zone collected in the dataset is UTC, not EST or PST, so in analyzing the chronology of events, we are taking this time difference into account. Unless otherwise specified, times referred to here are in UTC.
The impacts of data-gathering rules dictated by Twitter can be seen in gaps in our dataset, especially where there is a large sum of data missing from the morning and afternoon of January 7th. Also noteworthy is a gap between noon and 3 pm on January 8th.
Given these silences in our data, most of the data is actually from the 8th, the day Donald Trump got banned from Twitter. He was banned at 3:21 pm (8:21 pm UTC), which is about five hours before the last tweet posted in this dataset [4].
There are a few noticeable peaks in the dataset, namely, at 8 pm January 7th and 6 am January 8th. These peaks are not necessarily insignificant, but it is worth noting that because of Twitter API rules, the number of tweets collected for this dataset is limited, and these peaks may not be when the usage of the hashtag peaked overall. We can see that the most concentrated hour of conversation about the event in the hours we have data from was 8-9 pm on January 7th.
The first spike (8 pm Jan. 7 UTC, 3 pm Jan, 7 EST) occurred around when the first White House officials associated with President Donald Trump and White House security began to step down. This is also when Speaker of the House Nancy Pelosi spoke publicly about impeachment possibilities and the potential to invoke the 25th amendment to remove Trump from office (CNN). It is likely that this spurred on the conversation surrounding impeachment [4].
The second spike (6 am Jan. 8 UCT, 1 am Jan. 8 EST), is more difficult to explain. There were no significant updates in the news cycle at that time. That being said, this spike is relatively small (a jump of 2k tweets in an hour from the previous few hours) and occurs at waking time for those in UTC. It is likely that it represents the overlap of waking hours for those in the United States and those in other parts of the world.
These spikes in conversation reveal relatively little about what was going on during the course of this three-day period. Because our data from the 7th is limited to 7-11 pm UTC, we cannot evaluate true trends in conversation volume over time. The 8th has more data, but crucially is missing the hours between 11 am and 3 pm UTC, making it difficult to evaluate the potential cause of the drop in conversation between 11 am and 3 pm. It would make sense that usage of the phrase or words “capitol riot” would drop off as time went on, but the stark difference in volume between 11 am and 3 pm will remain unexplained until future researchers can obtain and analyze more data from over the course of the 6th, 7th, and 8th of January.
Critically speaking, this timeline reveals the lack of knowledge we really have about the conversation. The fact that it is Twitter data is limiting enough on its own, but moreover, it’s apparent that the conversation over the few days following the riot is difficult to document because of its high volume. Our picture of what was going on over Twitter is severely limited to those tweets the API allowed to be recorded within certain timeframes. As such, the following analysis is limited to a series of small snapshots of the overall dataset, and may not be representative of the conversation as it was occurring in real-time.
Our Work Plan
Due to the large size of our corpus and the limited computational power of our local computer, we developed meaningful ways to scale down the corpus while maintaining the corpus’s robustness. One such way we did this was by removing duplicate tweets from our corpus. The majority of the Tweets in our corpus (and Tweets generally) are retweets. So, we tallied the number of unique tweets that occurred in the corpus multiple times, then made a new dataset with only unique tweets. Importantly, each unique tweet had additional metadata on how many times it occurred in the original corpus. This way, we had a smaller dataset to work with, but one that maintained nearly all of the important information of the original dataset.
Extra Tweet information from the TAGS data, such as hashtags, and if the tweet contained an image and a respective hyperlink to the image, was also added as useful metadata. All Tweet’s body text was cleaned to remove textual artifacts. This data cleaning allowed for some early exploratory data analysis, such as visualizing hashtag data and body text tokens in a word cloud.
Ideology scores were run on the top 100 Retweeted Text-only tweets, and also on the top 100 Retweeted tweets containing images. This partisanship analysis allowed us to use ‘ideological position’ as a rough independent variable in our analysis. This was especially useful, as Twitter’s liberal bias is well documented, and the keywords ‘riot’ and ‘#riots’ used to collect the data introduce a certain bias in our dataset: the events at the capitol on January 6th may be called ‘riot’ by some, and a ‘demonstration’ by others. Introducing ideology metrics allowed us to better identify conservative voices within our corpus. See technical specifications below for more details on the partisanship score process.
For network analysis, to maintain the structural integrity, so to speak, of the retweet network, we used the entirety of our original corpus, including duplicates. Using TAGS data, we were able to extract directed edges and nodes tables with a python script written and made open-source by Doug Specht. The nodes table preserved information about the number of followers and friends (followers the user follows back) each user had as metadata for additional analysis. This was useful in determining the key players in the network, as well as visualizing the structure of the conversation itself. It led us to discoveries about the flow of information on Twitter during the days after the riots.
We also hand-annotated some tweets to fit into 8 categories: activism, celebrity, comedy, corporate, misc, news, personal, and politics.
Technical Specifications
Python and Pandas were used to clean and manage the original data from the corpus. The efficiency and reproducibility of this software made this an effective choice for the scale of our dataset. Excel was used occasionally, once the dataset was scaled to a more reasonable size. Tableau was used to create visualizations. Its robustness and interactivity made it a suitable choice for this project. The Voyant tools suite was used to aid in some preliminary analysis: it’s online, easy-to-use interface makes it ideal for quick exploration of data.
The ideology scores calculations were performed by using an Open Source R package Twitter_ideology. At a high level of description, this package functions by searching through a given user’s friends for ‘elites’ – accounts of celebrities, public figures, and media associations. Each of these ‘elites’ serves as a proxy for political orientation (The ‘elite’ account Fox News is associated with conservative ideology, for example). From the aggregate information of all the ‘elite’ accounts a user follows, an approximate ideological score is given for the given user. This score is on a binary scale: a lower score is more left, or liberal, and a higher score is more right, or conservative. A weakness of this approach is that it needs a user to follow at least one ‘elite’ user to give an ideology score approximation. So, we are unable to infer the ideology of a user who is either new to Twitter or does not follow popular accounts. Importantly, ideology scores are presented in the aggregate or with the user not explicitly identified, to protect the sensitive nature of this information.
The network analysis calculations were performed with a Python script that sorts data into two tables of nodes and edges. The script analyzes the text of tweets to see which users are retweeting others and sorts them into the tables described above accordingly. Gephi was used to visualize the data. The color represents modularity class, and other computations like eigenvector centrality and clustering coefficient were performed to gain a deeper understanding of the structure of the network.